CAISY AI Simulator FAQs
Skillsoft offers CAISY™, a Conversation Artificial Intelligence Simulator.CAISY provides interactive, scenario-based content powered by AI where a learner can practice new skills in a safe space by providing secure and realistic simulations. This AI simulation content allows learners to choose a role, practice specific skills by responding to AI prompts, and receive adaptive, personalized feedback to guide their development.
Having CAISY in your developmental toolkit can reduce the need for expensive, time-consuming, instructor-led training because the solution is scalable across departments, employee-levels, and situations. Employees can train at their own pace, eliminating scheduling conflicts and time away from work. When your employees receive the targeted training and coaching they need, it can lead to better decision making reducing your legal risks and increasing your operational efficiencies.
Use cases for CAISY include, but are not limited to:
- Role-playing in challenging scenarios such as coaching, conflict resolution, stakeholder negotiations, and handling HR related discussions
- Practicing responding to customer complaints
- Practicing strategic decision-making scenarios
- Developing and refining interpersonal communication skills
Because CAISY is powered by a generative artificial intelligence language model, it is not intended to replace professional advice or human interaction. The responses generated by this interface are based on statistical patterns learned from large data sets of text and may not always be accurate or relevant to your specific situation. Please use your own judgment when interpreting the responses and seek additional information or expert advice if unsure.
If you have any one of the Expert collections or the Skillsoft Leadership Development Program, you can make this content visible to learners by turning on the AI optimization and improvement setting. This setting is on by default for US-based learners.
The following responses to frequently asked questions will ensure you understand how this powerful content works.
If you need more details than what is provided below, please reach out to your Skillsoft account team. In addition, you can view the Skillsoft Responsible AI statement.
Learner interaction with CAISY
CAISY is primarily used for:
- Employee Development: Enhancing communication, leadership and interpersonal skills through interactive simulations.
- Scenario-Based Learning: Providing real-life, mimicking scenarios with personalized AI -driven feedback to improve learning outcomes.
- Emotional Safety: Creating a judgment-free environment where learners can practice and build confidence.
- Compliance Training: Addressing compliance scenarios such as protecting personal data and fostering workplace communication.
CAISY is not designed or intended to handle the following:
- Non-Workplace Conversations: Topics or scenarios unrelated to business or leadership contexts.
- Sensitive or Personal Data Handling: Scenarios involving personal, financial, or medical data.
- Training AI Models: CAISY does not train or fine-tune AI models using user inputs.
- Inappropriate or Adversarial Use: System guardrails block off-topic, unprofessional, or harmful inputs to ensure a safe experience.
CAISY is designed for anyone looking to improve communication and leadership skills in workplace situations. Ideal users include:
- Employees who are looking to strengthen communication, leadership, and interpersonal skills.
- HR professionals and managers who need to practice difficult conversations, such as performance discussions or conflict resolution.
- Sales and Service professionals who want to enhance their customer engagement and relationship-building skills.
CAISY simulates real-life variability, ensuring that no two conversations are exactly the same. This is particularly valuable for:
- Adaptive learning: Helps users practice handling different workplace challenges dynamically.
- Managing sensitive conversations: Prepares users for complex interactions requiring emotional intelligence.
- Conflict resolution: Encourages flexible responses based on context.
We have set the operating models to behave in a way that ensures a unique experience with real-time responses rather than responses based on static data sets.
On a learner's first access of CAISY, they must accept a disclaimer before continuing to use CAISY. This disclaimer contains links to more information regarding the Skillsoft Privacy Policy and an About CAISY summary. In addition, this disclaimer can include a custom privacy policy set by your organization. You can choose to have this disclaimer display every time a learner accesses a CAISY or just the first time.
Once they accept the disclaimer, they can begin a conversation. In addition, the following disclaimer displays below the text box where the user enters their response:
DISCLAIMER: Nothing that is discussed should be considered professional advice, and you should not assume responses in this conversation comply with your company’s internal policies. Please consult your company’s internal experts or a licensed attorney.
Learners can access the About CAISY summary and Skillsoft policies from the About link in the top navigation at any time.
AI simulator content shows to learners as the AI simulator content type. Learners can find this content in multiple ways.
- Enter CAISY in the Search box. The results show all AI simulator content.
- If searching for specific content, you can use the Type filter, and select AI simulation to show only AI simulation content for the keywords searched.
- From the left navigation bar, select AI Simulations.
- From the left navigation bar, select Library, then find the box titled Practice Conversations with CAISY and select Explore CAISY Scenarios to show only AI simulator content.
- When browsing a channel , look under the Practice tab for AI simulator content. Not all channels have AI simulator content.
Each scenario is introduced by an avatar that is generated with AI text-to-video. After the introduction, the learner can either interact by typing or using speech-to-text (STT) and text-to-speech (TTS) services for more immersive and natural interaction.
When the conversation is over, the learner will receive a rating and evaluation.
Yes. If learners have the Skillsoft Percipio mobile app, they can launch AI simulator content from the app.
If learners are trying to launch AI simulator content from a browser app on a mobile device, they may need to turn off pop-up blockers for that browser app to play AI simulator content.
AI simulator content is licensed with any one of the Expert collections or the Skillsoft Leadership Development Program. You can check your collection from the License Pools page. Reach out to your Skillsoft account team if you have questions. Make sure your license pools have been entitled to audiences, license distribution, so users can see their content including CAISY simulations.
You might also need to check your list of hidden content.
Skillsoft provides CAISY scenarios for customers who license Business or the Skillsoft Leadership Development Program (SLDP).
Learners can find this content in multiple ways:
- Enter CAISY in the Search box. The results show all AI simulator content.
- If searching for specific content, you can use the Type filter, and select AI simulation to show only AI simulation content for the keywords searched.
- From the left navigation bar, select AI Simulations.
- From the left navigation bar, select Library, then find the box titled Practice Conversations with CAISY and select Explore CAISY Scenarios to show only AI simulator content.
- When browsing a channel , look under the Practice tab for AI simulator content. Not all channels have AI simulator content.
If you license Skillsoft Compliance content and access it directly within the Skillsoft Platform library, you see 4 compliance simulations under the Legal Compliance area. If you license Skillsoft Compliance content and access it in the Percipio Compliance interface, you will not see the 4 simulations.
A learner can complete up to 50 simulations in a day. The simulations can be all from one topic or from multiple topics.
The system is designed to support hundreds of concurrent learners.
The CAISY™ AI simulator rates your responses as if it were a human resources representative employing best practices for the given situation. The responses are subjective and non-precise, focusing on qualitative factors. The system is not designed to answer fact-based questions but to facilitate conversational simulations, emphasizing adaptive and context-sensitive interactions.
You will get one of the following ratings provided you took the simulation in Practice mode:
- Novice (0-9 points): Novice means that you are starting with very limited familiarity on the topics critical for the skill.
- Aspiring (10-49 points): Aspiring means that you have demonstrated minimal capabilities for the specific skill and should make an investment in learning to achieve proficiency.
- Developing (50-69 points): Developing means that you have some proficiency with the specific skill and only need to close a few knowledge gaps to achieve proficiency.
- Proficient (70-89 points): Proficiency means that you have met the criteria for applying your knowledge with the skill to practical challenges in your work. We recommend you strive to achieve a minimum level of Proficiency for the skills you are developing.
- Advanced (90-100 points): Advanced means that you demonstrate a thorough understanding of the skill and may be a candidate to mentor other learners within your organization.
The overall rating is based on four criterion:
- Scenario objective: How well did you meet the objective set out by the scenario. This measures direct alignment with training goals and assesses whether you achieved what the scenario was designed to teach. It emphasizes practical application and outcome relevance - ensuring the conversation accomplishes the intended result (e.g., resolving a complaint, persuading a stakeholder). The system assigns this criterion the highest weight (70%) to emphasize mission completion.
- Professionalism: Were you professional, such as showing empathy and support, being guiding and direct, and using manner? Professionalism maintains trust and keeps the conversation respectful and credible. It adapts tone and style based on context. In Customer Service, you show empathy and offer solutions with a moderately formal tone. In Team Collaboration, you communicate directly and efficiently with appropriate informality. In Business Exchange, you use a formal, precise, and polished tone. This criterion also reflects the Four Universal Pillars - Clarity, Brevity, Tone, and Politeness - and helps you avoid negative impressions that could harm relationships or brand reputation.
- Coherence: Were your responses thoughtful and follow a common thread and make sense to what was being asked? Coherence ensures logical flow at both the sentence and conversation level. It helps the recipient follow your message without confusion or unnecessary topic jumps. It supports moving toward a resolution or clear next step. It prevents “referential drift”- dropping or abandoning points mid-conversation - and reduces ambiguity from vague pronouns or unclear terms like “this,” “that,” or “it.”
- Efficiency: Did you ramble on or were you succinct but personable in your response, getting to the point quickly? Efficiency respects the other party’s time by keeping your message concise and purposeful. It aligns your response with the goal, improves comprehension, and reduces effort. It also clarifies next steps and ownership. In Customer Service, you anticipate and address likely follow-ups. In Team Collaboration, you deliver concise handoffs with clear ownership. In Business Exchange, you use precise structure with well-scoped actionables.
Ratings and evaluations are logged in the AI database and logs with an abstract user ID. This is because both the username and any other personal data is not stored within the AI database or logs.
Skillsoft Platform reports show the CAISY rating score associated with each learner just like with any other content. Admin users with access to reports containing that user can see the user's rating.
You can copy, paste, and edit the following text in an email if you’d like to invite users to use AI simulator content.
Subject: Announcing a true interactive learning experience!
We are excited to share that you can now practice your skills real-time by responding to AI prompts. Choose the scenario and behavior, then enter one or more responses. The AI simulation shares adaptive feedback based on your responses. You can practice up to 50 different scenarios a day for the most effective learning experience.
To locate the AI simulator content:
- Search for AI simulator and find the following simulations:
- Select Launch to start the simulation. You may need to allow browser pop ups to continue.
- Expand the left navigation to optionally change your experience.
- For the Scenario mode, you can choose either:
- Practice: In this mode, you practice the skill presented by the simulator. Use this mode when you want to practice coming up with your own words and phrasing to handle the situation.
- Role model: In this mode, you allow the AI Simulator to model the skill based on you acting in the opposing role. Use this mode if you are not sure where to begin and want ideas for best practices. When you use CAISY in this mode, you do not get a score.
- Guiding: In this mode, you practice the skill presented by the simulator. After a few messages, you receive a message from the AI Coach that shares how you are progressing in your conversation. When you use CAISY in this mode, you do not get a score.
- The behavior you choose guides how the AI simulator responds to your input. By selecting different behaviors, you can practice the same situation and get different AI responses to your input.
- For the Scenario mode, you can choose either:
- Read or play the case scenario introduction, then enter a response. You can either type or speak your response. Do not use real names, personally identifiable information, company proprietary, or confidential information in your responses. The AI simulator responds automatically and waits for your response. CAISY either continues the conversation asking for additional input from you up to 15 times, or if it deems it has enough input to evaluate your responses before reaching the 15-response limit, it closes the conversation.
Happy Learning!
There are several factors that can trigger conversation completion.
- When the AI model detects that the conversation has reached a logical conclusion, such as the sale completed.
- When the conversation reaches the 20-turn limit.
- When the learner enters or speaks the word End in the conversation.
- When the leaner selects the End scenario link under the conversation.
If the learner ends the conversation when there are less than 2 messages, they do not see an evaluation.
If a learner starts a conversation and closes the window before reaching the end, the conversation is considered Started.
If you launch a CAISY and have at least one interaction and close the window or let it time out, the conversation is considered started in reports and on your Activity page.
CAISY simulations are available in many languages. To see if it is available in your language, you can check out this table.
To complete a scenario in one of the available languages simply change to the language you’d like. We will also be curating CAISY simulations in pages on the corresponding language sites.
Any data that you share helps Skillsoft improve the service. For example, we use your feedback to increase the effectiveness of AI safety policies.
You can provide feedback in two ways: directly to Skillsoft and to your admin.
Directly to Skillsoft:
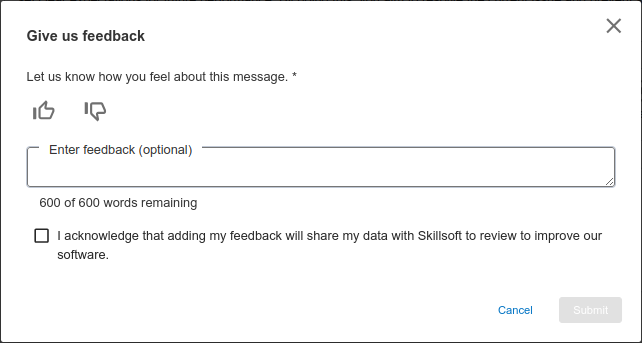
While taking a CAISY, select the thumbs up/down icon. This opens a dialog box for you to rate the response and provide reviewer comments. Once open, you can select thumbs up or thumbs down and offer an explanation. Optionally check the box: I acknowledge that adding my feedback will share my conversation with Skillsoft to review to improve our software so that Skillsoft can fully evaluate your feedback in the context of the conversation you had and act on it.
To your admins:
To provide feedback to your admins, select the Give scenario feedback link at the end of the scenario, if enabled for your site. By using the Learner feedback dashboard, they can evaluate your feedback with others' feedback to understand the effectiveness of CAISY in your organization
Feedback learners submit via the thumbs up icon is logged in the conversation logs.
The feedback is periodically reviewed by the Product teams for sentiment, requested improvements, and potential issues. Appropriate enhancements or improvements are considered and prioritized.
CAISY content management
Yes. AI simulator content is represented with the Asset type of Linked content and the Content type of AI simulator.
You can assign and promote AI simulator content. You can also add it to custom channels, journeys, and learning programs and find it in reports with the Asset type filter equal to Linked content and Content type equal to AI simulator.
If you license Skillsoft Compliance content and access it directly within the Skillsoft Platform library, you see 4 compliance simulations under the Legal Compliance area. If you license Skillsoft Compliance content and access it in the Percipio Compliance interface, you will not see the 4 simulations. Contact your Skillsoft account team if you are interested in using CAISY compliance simulations.
The four compliance simulations located in the Compliance area of the Skillsoft Platform library are:
- Best Practices for Protecting Personal Data (PII)
- Delivering Respectful Communication to Employees
- Handling a report of Harassment or Discrimination
- Strategic Business Activity or a Bribe?
Yes. When learners use CAISY, you see content under the reporting Asset type filter as Linked content and a Content type of AI simulator. The platform tracks how long the learner interacts with the content, the start date, and the end date.
The best report to use to see learner activity is the Learner Activity report and filter the Category column for AI Simulator to see simulation starts, completions, and duration for each user who consumed the content. To see aggregated data about each simulation, you can use the Content Access report which shows total unique users who accessed the simulation, total accesses, average duration, and total completions.
In some cases CAISY completions may not show immediately in reports. There could be a delay of a day or so.
Yes. If your LMS supports practice content, you will get the AI simulator content by default in your LMS. Tracking simulation data back to the Skillsoft Platform from the LMS is also supported.
CAISY is a feature of the Skillsoft Platform, which conforms to WCAG 2.1 A and AA accessibility standards with some exceptions noted in its VPAT Conformance Report.
Note: All non-conformances related to the Conversation AI Simulator (CAISY) have been remediated as of February 2024.
Yes. You can hide AI simulator scenarios you do not want your learners to see. To hide individual scenarios, follow the instructions for Hiding individual content items.
Yes. You can add a custom policy specific to your organization’s AI policy. You can require learners to accept it just the first time they launch a CAISY simulation or every time they launch a CAISY.
Data collection and usage
Skillsoft always logs the AI side of the conversation, time stamps, AI options used during the conversation, ratings, feedback, if guardrails are triggered, and other non-user specific data for reporting and analytics.
Skillsoft only logs the learner side of the conversation if the admin setting: AI optimization and improvement is enabled and the learner has not turned it off on their side. Skillsoft also collects the learner side of the conversation if the learner provides feedback and checks the box to share the conversation.
Learners can opt out of having their side of the conversation shared with Skillsoft, even if it is enabled for your company:
With the
Turn off: Allow Skillsoft to collect, store, and analyze my conversations in order to improve the
Select Save.
- All data entered is encrypted in transit and at rest.
- The information that the learner enters into
-
The LLM does not store any conversation data.
- Skillsoft stores AI conversation data in authenticated and encrypted AWS storage.
- CAISY does not collect or store personal data from users unless they enter the information as part of the conversation.
Feedback learners submit via the thumbs up icon is logged in the conversation logs.
The feedback is periodically reviewed by the Product teams for sentiment, requested improvements, and potential issues. Appropriate enhancements or improvements are considered and prioritized.
- Any data that you share helps Skillsoft improve the service. For example, we use your feedback to increase the effectiveness of AI safety policies.
- Skillsoft has a process for improving
- Only limited Skillsoft employees can access and review conversation data.
Yes. All data entered is encrypted in transit and at rest.
Third party LLM providers do not log or have access to inspect any AI inputs or outputs. Skillsoft only stores conversation data in authenticated and encrypted AWS storage. Only limited Skillsoft employees can access and review conversation data.
Skillsoft stores this data per the terms in your contract. Skillsoft can delete
The STT utilizes the same service as Microsoft Teams. The audio that the user speaks is sent from their browser directly to the Azure cognitive speech service. The Azure speech service transforms the audio to text and returns it to the user's browser where it is entered into the text input box. After transforming the audio to text, it is garbage collected and not saved anywhere.
Microsoft does not log or save the input or output from the cognitive speech services.
For more information, see:
No.
For more information, see:
- The information that the learner enters into
-
The LLM does not store any conversation data.
- Skillsoft stores AI conversation data in authenticated and encrypted AWS storage.
- CAISY does not collect or store personal data from users unless they enter the information as part of the conversation.
Yes, it is possible to delete per user and per organization upon request. Reach out to our Support team for assistance.
The Skillsoft Percipio Platform is a multi-tenant system where all tenants share the same services and resources. Customer data is isolated with tenant keys and/or S3 buckets.
CAISY outputs are evaluated through a combination of Subject Matter Expert (SME) reviews, continuous monitoring, and automated guardrails to ensure accuracy, relevance, and appropriateness. The following are in place:
- SME evaluation: Experts assess outputs based on correctness, appropriateness, and contextual relevance, ensuring responses align with best practices.
- Continuous monitoring: CAISY detects runtime anomalies and triggers alerts if issues arise, allowing the responsible team to address them promptly.
- Guardrails and qualitative testing: Built-in safeguards filter out inappropriate or off-topic inputs, ensuring consistency in conversational flow.
- Hallucination detection: CAISY flags responses that deviate from expected topics.
Because CAISY outputs are context-specific and dynamic, SME-driven assessments and real-time monitoring are essential for maintaining response quality.
Guardrails for addressing inappropriate conversations
We have concurrent GenAI model prompting for every user input to test for inappropriate inputs. If we discover inappropriate inputs, we stop the conversation and inform the learner. The GenAI model also has it's own guardrails to flag inappropriate input which we also monitor. If we discover inappropriate input from that perspective, we also stop the conversation and inform the user.
One guardrail checks if the conversation is inappropriate. If the conversation is inappropriate, we stop the conversation and let the learner know their response is inappropriate.
Another guardrail checks if the user made an unrelated comment. If it is the first occurrence of unrelated content, we will ask the learner to redirect the conversation back to the topic at hand. If the learner continues down the unrelated path, we stop the conversation.
The guardrails allow for a learner to have a
We either warn learners and guide them back on-topic, to be more professional, or we stop conversations that cross the boundaries set by the guardrails.
In our ongoing efforts to enhance
We also make our best efforts to minimize false negatives, where the incident doesn't trigger the guardrail and should have. Our goal is to catch most inappropriate or off-topic content without overly tripping the guardrails. This balancing act requires us to prioritize the reduction of false positives over false negatives to ensure a smoother and more effective conversation flow.
Our testing dataset encompasses a broad range of content categories to thoroughly test
The primary categories covered in our testing dataset include:
- Threatening: This category includes statements or language that could be perceived as threatening or indicative of impending harm, ranging from subtle threats to explicit declarations of intended violence.
- Sexual: Test cases in this category cover sexually charged language and themes, from subtle innuendos to overt descriptions of sexual acts.
-
Hate: This category tests
- Harm: Test cases involve language that could be interpreted as encouraging or glorifying self-harm, suicide, or violence towards others.
- Harassment: This category assesses
- Violence: This category focuses on language involving graphic depictions of violence, gore, or physical harm, distinct from outright threats.
- Bias: This category tests
We look for both direct input, where the problematic nature of the content is clear and explicit, which could include:
- Overt insults, slurs, or derogatory language directed at individuals or groups
- Explicit threats of violence, harm, or abuse
- Unambiguous expressions of bias, hatred, or discrimination
- Graphic or detailed descriptions of sexual acts, violence, or illegal activities
And indirect input, where the problematic nature of the content is implied, subtle, or contextually dependent, which could include:
- Veiled or implicit threats that rely on innuendo or suggestion
- Backhanded compliments or microaggressions that subtly demean or stereotype
- Sarcasm, jokes, or memes that mock, belittle, or promote harmful attitudes
- Seemingly innocuous statements that, in a specific context, could enable or encourage problematic behavior
By evaluating
This dual focus on content and articulation mode enables us to refine
CAISY validates and sanitizes all customer-provided inputs before processing them. Input variables such as behavior settings, modes, prompts, are checked against expected formats, allowed values, and predefined validation rules in the backend services.
Guardrails are used to detect inappropriate or off-topic inputs. If inappropriate input is identified, the platform stops the conversation and informs the learner that the response violated acceptable use expectations. If a learner moves significantly off-topic, the platform initially redirects the learner back to the intended discussion. Continued unrelated responses may result in the conversation being ended.
These measures help ensure that customer inputs are received, interpreted, and processed correctly.
We don't attempt to address jailbreaks because in the event of an adversarial attack, the generated output would only be visible to the affected learner and would not have any bearing on the experiences or outcomes of other learners. The localized impact of such an attack minimizes the overall risk to our platform and its users.
Because
Each scenario has a detailed description that includes guidance which guards the conversation to detect and prevent bias and inappropriate responses. In addition,
Because
While it is not zero, it is low and extensive testing has not revealed issues that have raised concerns.
It is improbable
In addition,
Extensive Quality Assurance testing has not revealed significant issues with outputs.
Users are warned that responses might not be accurate.
Because
Please submit feedback so we can review and improve any rare mistake that may occur.
CAISY is continuously tested, monitored, and refined to ensure reliability and fairness across different workplace training scenarios. The following measures are in place:
- Testing Performance in specific contexts and conditions: CAISY undergoes scenario-based testing to validate effectiveness in coaching, conflict resolution, leadership training, and customer service interactions. Performance is tested across diverse user interactions to ensure adaptability to different communication styles and workplace environments.
- Processes for detecting and addressing under-performance: Automated monitoring tools flag inappropriate and off-topic responses. Subject Matter Experts review AI-generated feedback to refine scenario logic and improve conversational flow.
- Customer assurance and compliance mechanisms: Regular AI fairness evaluations to detect and mitigate biases in responses, and regulatory compliance reviews ensure alignment with GDPR, SOC2, and FedRAMP security standards.
Security
In addition,
- Encryption: The LLM automatically encrypts the user's data. The encryption protects their data and helps customers meet organizational security and compliance commitments.
- Data Security: The LLM offers us the ability to do regional deployments to ensure EU hosted data is processed in EU and North America hosted customers data is processed within North America.
- Limited Access Review: Modified Abuse Monitoring -
The LLM does not store any conversation data.
Additional security layers help to mitigate biases in training data, promote fairness, reduce the spread of false information, and prevent offensive or inappropriate responses through the interactions that learners have with
Every time a conversational scenario takes place, the system is monitoring for abuse, correct context, and scenario accuracy. For example, if a learner were to initiate an off-topic or inappropriate conversation with
Data is encrypted in flight with TLS 1.2+ and encrypted at rest per FIPS 140-2.
The data is persisted within the FedRAMP authorization boundary where limited and authenticated access is required.
The current models that are used are Commercial off-the-shelf (COTS) models. The models are created by the LLM and hosted by
No, we do not train or fine-tune AI models used by
No, but it does use OpenAI models of which the core foundation model is similar to ChatGPT.
MS Azure OpenAI uses default content filters for safety to prevent inappropriate inputs and responses.
- Encryption: The LLM automatically encrypts the user's data. The encryption protects their data and helps customers meet organizational security and compliance commitments.
- Data Security: The LLM offers us the ability to do regional deployments to ensure EU hosted data is processed in EU and North America hosted customers data is processed within North America.
- Limited Access Review: Modified Abuse Monitoring -
The LLM does not store any conversation data.
Yes. The Skillsoft Platform has been FedRAMP authorized since March 4, 2022. A Significant Change Request (SCR) for the technologies supporting the
You can find Skillsoft's FedRAMP authorizations at:
- Skillsoft Platform Package: FR2118043605
- Microsoft Azure Commercial Cloud: F1209051525
Yes. CAISY adheres to EU AI Act, GDPR, and NIST AI Risk Management Framework. We also engage with third-party auditors to validate alignment with applicable laws and best practices.
CAISY should be considered as posing limited risk according to the EU AI Act. This is justified by the stringent mitigation measures, including custom guardrails, encryption, and regulatory compliance frameworks that are in place. Users are advised about interacting with an AI powered solution. Third-party audits further validate the safety and reliability of the platform.
Yes. Go to Site settings > Policy Management > Custom Policies > AI Policy.
CAISY supports both X-Frame-Options and Content-Security-Policy security headers to prevent click-jacking attacks.